
More and more businesses are now leveraging on their knowledge of what the customers want through feedback and reviews to improve their business processes. Thus, the ability to capture and understand the customers fast is now the real game among enterprises. A lot of tools were already being used by large companies to acquire and monitor customer sentiments.
In this post, we will try to understand how Natural Language Processing (NLP) can be used to analyze languages, specifically on movie reviews, and how businesses can use it to analyze the change in behavior of consumer preferences. We would be using an open-source tool called Empath.
Empath is a tool to analyze text across lexical categories similar to Linguistic Inquiry and Word count (LIWC) – commonly used by researchers. It “analyzes text across 200 built-in, pre-validated categories generated from common topics in the web” [1]. It provides a numerical representation for each category as analyzed by content. It addresses the limitation of LIWC which only analyzes text across only 40 topics.
We have managed to acquire compiled data of movie reviews from [2] which was first used by Pang and Lee in [3]. These are numerous film reviews from known film critic and personalities such as Dennis Schwartz, James Berardinelli, etc. that are pre-processed and stored in a .txt file format.
Prepare Data
We first load necessary libraries we need for our analysis and set up the list in which we will do the analysis on.
| # Load libraries | |
| import os | |
| import logging | |
| from empath import Empath | |
| import pandas as pd | |
| # Set up folder locations | |
| source_folder_path_list = [] | |
| source_folder_path = "C:/Users/Marriane/Documents/GitHub/empath-on-movie-reviews/data/scale_whole_review.tar (with text)/scale_whole_review/scale_whole_review/" | |
| folder_list = ["Dennis+Schwartz/txt.parag", "James+Berardinelli/txt.parag", "Scott+Renshaw/txt.parag", "Steve+Rhodes/txt.parag"] | |
| for folder in folder_list: | |
| folder_loc = source_folder_path + folder | |
| source_folder_path_list.append(folder_loc) | |
| print(source_folder_path_list) |
Main Analysis
Then, we perform the operation on a for loop to analyze all the .txt files in one execution. Lastly, we store our data frame in a .csv file.
| if __name__ == "__main__": | |
| lexicon = Empath() | |
| result = lexicon.analyze("the quick brown fox jumps over the lazy dog", normalize=True) | |
| df0 = pd.Series(result, name = 'KeyValue') | |
| logging.getLogger().setLevel(logging.INFO) | |
| col_names = df0.keys() | |
| df = pd.DataFrame(columns=col_names) | |
| for folder in source_folder_path_list: | |
| txt_list = [] | |
| for file in os.listdir(folder): | |
| if file.endswith(".txt"): | |
| txt_list.append(file) | |
| for txt_i in txt_list: | |
| txt_file_name = txt_i | |
| #logging_str = "Coverting " + txt_i | |
| #logging.info(logging_str) | |
| txt_full_path = os.path.join(folder, txt_file_name) | |
| try: | |
| txt_file = open(txt_full_path, 'r') | |
| lines = txt_file.readlines() | |
| lexicon = Empath() | |
| result = lexicon.analyze(lines, normalize=True) | |
| new_result = pd.Series(result, name = txt_full_path) | |
| new_result.index.name = 'Key' | |
| new_result.reset_index() | |
| df = df.append(new_result) | |
| logging.info(txt_i, " succesfully analyzed") | |
| except: | |
| logging.info(txt_i + " open failed") | |
| df = df.dropna() | |
| # Clean the data frame | |
| df['Details'] = df.index | |
| df['Reviewer'] = df['Details'].str.split("/").str[11] | |
| df['Text file'] = df['Details'].str.split("/").str[12] | |
| df = df.set_index(['Reviewer', 'Text file']) | |
| df = df.drop(['Details'], axis = 1) | |
| df.to_csv('./data/output/Empath-on-movie-reviews_results.csv', sep=',', encoding='utf-8') |
Examine the Data
It is probably a bit overwhelming to look at all the numbers obtained from those numerous reviews examined. Perhaps, why don’t we have a closer look on one of the examples we just had. Examining the results of one of the reviews we looked at by Dennis Schwartz, it states that
“…This is an obscure Bela Lugosi film and it’s not bad. Ellis is the dame with class. She sings the happy tune ‘Bluebirds on wallpaper decorating our dreams.’ Bela’s the bad guy with a foreign accent. His fans will love him here, as this film has been restored recently and is now watchable.“
This is a review on the film ‘Postal inspector’ last 2001. See full review here. The review circulates on what the characters do to live and what they do to survive their own circumstances. With that, the result of applying empath is summarized below.
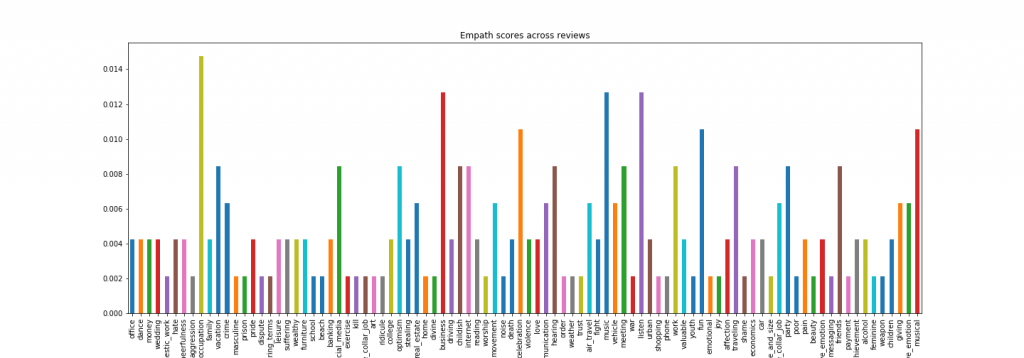
Based on the chart above, occupation, business, music and listen are the top 4 categories found after analysing the text using empath. Now, let’s try to go back to the text and check what could have probably contributed to the high scores.
First, occupation. If we are to go back to the full review and get some key words which might have resulted to a high empath score on occupation, we will find phrases like good work, job, and works for the post office. For business, things like shady owner of a prominent nightclub. Lastly, for music and listen, we have nightclub singer, sing to the passengers, and sing at the nightclub.
There you go! You can now start examining your own texts and see how it’s interpreted when applied with empath.
References
- Fast, E., Chen, B., Bernstein, M.S. (2016). Empath: Understanding Topic Signals in Large-Scale Text. Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems. pp. 4647-4657. USA CA, San Jose. DOI: http://dx.doi.org/10.1145/2858036.2858535.
- Movie Review Data. www.cs.cornell.edu/people/pabo/movie-review-data/ . Accessed on November 21, 2018.
- Bo Pang and Lillian Lee. Seeing Stars: Exploiting class relationships for sentiment categorization with respect to rating scales. Proceedings of ACL. 2005.